Differentiating how "bots" vs. "humans" interact online

How do bots and humans interact differently online? What about "good humans" vs. "bad humans"? How can we define and reduce the problem of identifying fraudsters online?
This article was written in April 2023. While most of the content is likely evergreen, note that technology moves fast and some specifics may be outdated.
Defining and reducing the fraud identification problem
We can consider the problem of identifying fraud online to be a multiclass classification problem. For each online transaction, we are ultimately trying to predict whether the transaction is performed by a good bot, a bad bot, a good human, or a bad human.
This is not an easy problem. There are two intrinsic challenges:
- Good vs. bad: It is tricky to identify whether a given actor is good or bad because it requires us to guess the actor's intent. A single transaction provides a very limited view of what the actor is doing. Instead, we will need to analyze the actor's historical transactions. This makes feature computation more challenging, as we have to consider a lot more data!
- Bot vs. human: Not all bots are bad, and not all humans are good! One of the reasons why it's so challenging to determine whether an actor is a bot or a human is that these are not two absolutely distinct classes – It is perhaps more accurate to consider the classes on a spectrum, with bots on one end and humans on the other end. A transaction could be:
- Performed (purely) by a human – This is what we typically consider to be a "legitimate" user
- Performed by a human, using some type of tools. This is a broad category that encapsulates people using VPNs, browser extensions to hide their tracks, antidetect browsers, scripts to partially automate transactions, and so on.
- Performed (purely) by a bot. The entire transaction is scripted.
Given that "good vs. bad" and "bot vs. human" are actually orthogonal, it is perhaps easier to split this four-class fraud identification problem into two separate problems:
- Is this transaction performed by a bot or human?
- Is the "user" good or bad?
Here are some possible scenarios:
| Identity | Good / Bad | Examples |
|---|---|---|
| Human | Good | You and I. And most users, hopefully. |
| Bot | Good | Aggregators (usually). Search indexers (e.g. Googlebot). |
| Human | Bad | Fraudsters. Human click farms. |
| Bot | Bad | Credential stuffing. Unwanted scrapers. Man-in-the-middle bots. The list goes on... |
A useful approach to identifying web traffic is to first isolate the bot traffic, then isolate the "bad humans" (i.e., fraudsters). This is useful especially for large websites with significant traffic, as a good amount of traffic is likely to be automated. Recap: A quick indicator of the prevalence of bots is how non-diurnal the traffic pattern appears to be.
To top it off, what or who do we determine to be an "actor" anyway? The concept of "identity" is pretty hazy online. There are several candidates:
The username claimed by the user. This is who the user claims to be. We commonly accept knowledge of a secret, like a password, as proof that this is a legitimate claim, but there are many issues with that. Passwords can be leaked, and even multifactor authentication can be spoofed.
The person "behind the screen". This is the actual human performing the transaction. Unless you require the user to take a photo or video for each transaction, it is pretty much impossible to identify the human. Even if you completely disregard user friction and require such a photo or video (e.g., for safety and security reasons -- such as for an Uber driver at the start of each shift, or for a Doordash delivery driver), there is no guarantee that the human performing the transaction is the human trying to authenticate.
The device on which the transaction is performed. This is perhaps easier to identify more accurately than the other two, but it has limited utility on its own.
This is why it often does not make sense to predict whether a given "user" is a bot user or not – A username can be used by a human and then taken over by a bot. Someone's legitimate device can also be commandeered to perform malicious activity, such as participating in a botnet.
A detour on aggregators
Financial aggregators are services that help users aggregate data from various financial institutions. You might have used tools like Mint (owned by Intuit) to consolidate your spending and account balances in one place. Or you might have applied for a loan online, where the loan originator offered you an option to connect your bank account -- That service was probably powered by Plaid. Other examples include CashEdge (now part of Fiserve), Yodlee, and Finicity. These provide a plethora of services such as bill payments, peer-to-peer funds transfers, and account ownership confirmation.
There are also other types of aggregators. For example, insurance aggregators like Gabi connect to your online insurance accounts and try to find you a better insurance quote. Travel aggregators like Kayak scrape airlines' and hotels' websites for pricing and availability data, aggregate them, and provide them to end users.
Aggregators are best thought of as a tool that is by itself neutral, but that can be a double-edged sword: They can be used for good or for bad. Consumers generally benefit from them, but the same cannot be said of service providers, whose websites see lots of bot traffic and are often scraped or accessed against their fair use policies. Many financial institutions, for example, were particularly unhappy with how Plaid accessed their online banking systems. They also dislike being disintermediated from their own customers!
There is also a security angle, particularly for financial aggregators: Handing over your credentials to an aggregator is essentially providing a third party with your front door keys, and there is no guarantee of what they will do once they are inside your house (account). You might authorize an aggregator only to fetch your checking account balance, but what if the aggregator also performs a transaction, or fetches your personal data? For tools like Gabi, what if they also had the power to terminate your insurance policies indiscriminately?
Identifying what you are: How bots and humans interact differently online
Last week, we learned how human and bot traffic might appear differently within server logs, and how to distinguish them using only the information available in server logs.
That is often a good first approach, but as with any data science problem, the more data we have, the better we can do.
It is imperative that we consider the types of signals that we can obtain within the browser itself, to profile the user's actual behavior both within a page and across pages.
We have already touched on how to collect signals, such as keyboard and mouse events and screen and browser dimensions. But how do these signal values typically differ between humans and bots?
Let's look at a case study.
Website disclaimer page
On a particular website that allowed users to perform searches for some records, users had to click through some terms of use on a page before they could proceed with using the website. This was the page that they encountered (text blurred out to anonymize the website):

This page would be shown before every use of the website, so there was no way to get around this page by directly accessing the main website. Hence bots that wanted to scrape search results first had to get past this page. Note the "Accept" and "Decline" buttons.
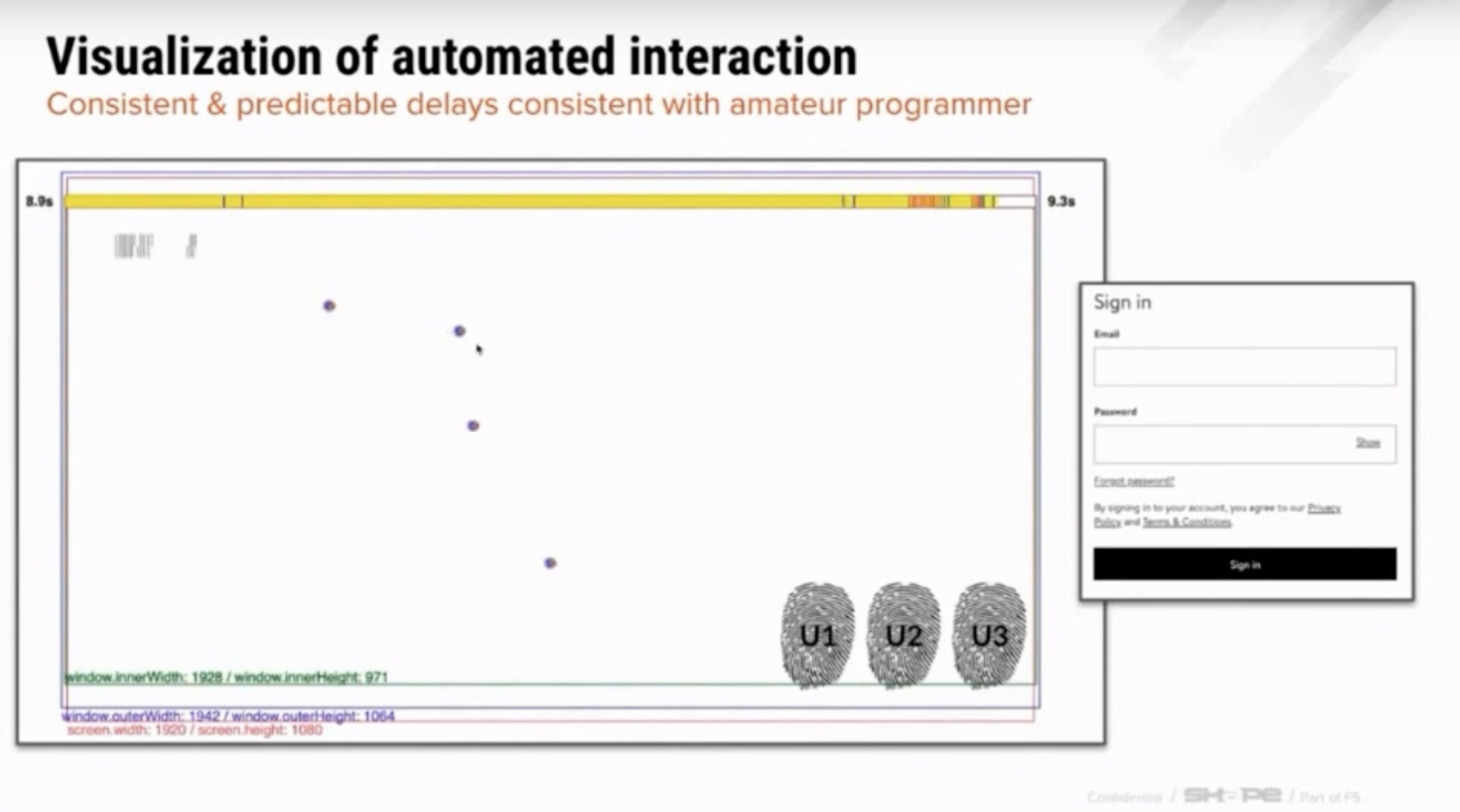
The illustration below highlights the difference between how humans and bots get past this page. This was generated over many thousands of actual and historical interactions for both humans and bots.
The green dots represent mouse movement events, i.e., the exact locations of the mouse cursor. The red dots represent mouse clicks.

Humans are clumsy, while bots are precise
Human behavior

The red dots (mouse clicks) on the left are rather diffuse and are spread across a hazy rectangular area that is roughly the shape of the "Accept" button. There is also a very faint patch of red on the right, which probably signifies a tiny fraction of people clicking on the "Decline" button. There is a lot of entropy in where people actually click -- They usually manage to click on the button itself, but some will click outside the button.
Also, note that mouse movements are highly random – Even though people are obviously moving their cursors towards the "Accept" button, the paths they take appear similar to random noise when their cursor movements are overlayed on top of one another. (Looks really similar to Brownian motion!)
Bot behavior
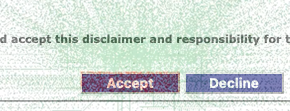
On the other hand, bots are extremely precise. They always click perfectly on target, and never decline the terms of use. Look at how perfectly centered on the "Accept" button the red dots are!
Their mouse cursors also move in perfectly straight lines to the click target. This is actually fairly sophisticated: most basic bots will not even simulate any mouse movements if they can get away with it -- It is easier to simply simulate a click on the button of interest. This website probably has some anti-bot protection in place that requires some amount of mouse movements (or keystrokes) before letting users enter.
If this website implements additional security measures to detect such "low entropy" mouse movements and clicks, the bots' creator (or controller?) will probably generate some artificial noise for mouse movements and clicks. In this way, we are always playing a cat-and-mouse game with bots, with developers making their bots more sophisticated to circumvent detection. These bots will continue to become more sophisticated until the potential reward is no longer worth the effort.
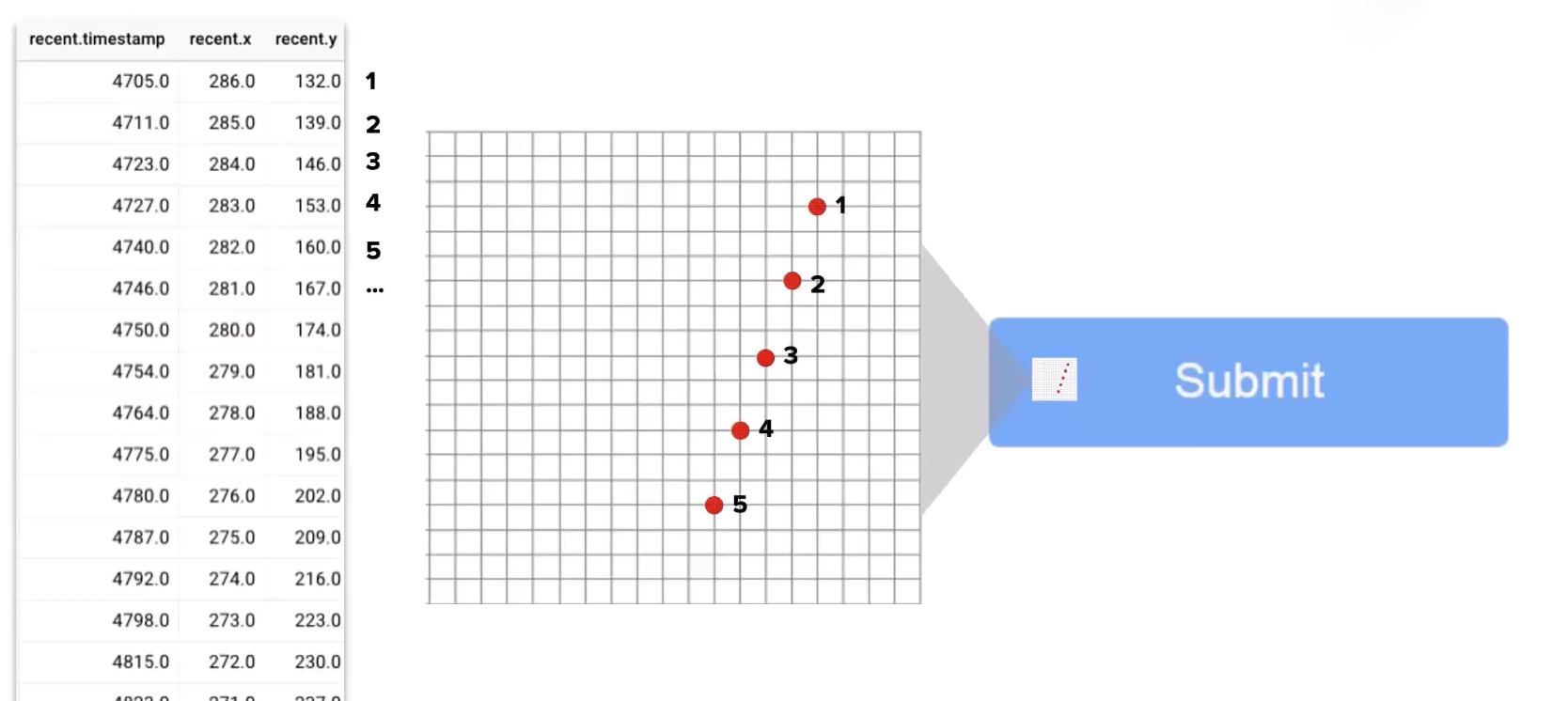
Here is a screenshot showing the specific coordinates of a bot-like mouse movement. No human can ever move the mouse in a perfectly straight line for more than a short distance -- just try!
Note that there is some intrinsic noise to the timestamps, even though the cursor locations are sampled at regular intervals; this is an artifact of the signal collection process.
Putting it all together
Adapted from a briefing in July 2021 titled "Financial Aggregators: Friends, Foes or Attack Surface" by Dan Woods, then VP Shape Intelligence Center at F5 Networks. Original video link: https://www.youtube.com/watch?v=bS9QqPhExQo
The two examples below allow you to pause and look carefully at the differences between humans bot keystrokes. Notice how much entropy there is in the time intervals between the human's keystrokes versus how regularly and tightly packed together the bot's simulated keystrokes are:
Identifying intent: How legitimate human users navigate pages differently than fraudsters
It is considerably more challenging to identify a "legitimate human" from a "human fraudster". After all, both are humans and so can be expected to have the same amount of entropy in their mouse movements and keystrokes. They would also both be using "normal" browser environments and networks.
That said, there are still some important differences between legitimate humans and fraudsters that we can leverage. Here are some examples:
Fraudsters might need to log into and access numerous accounts, while legitimate humans would usually access the one or two accounts that they control. (Perhaps a personal account and one belonging to a spouse.)
Fraudsters might need to interact very efficiently with the website, as they might be repeatedly performing the same transactions over and over again. This would almost certainly mean that they are using keyboard shortcuts to navigate the page -- For example, by pressing "Tab" to advance to the next form field, or "Enter" to submit a form, as opposed to using the mouse to do so.
Fraudsters might need to arrange their browser differently on their screen, as opposed to legitimate users. For example, they might resize their browsers to the absolute minimum width that the website can support (and still render well), and devote the bulk of their screen real estate to showing things like credential lists.
Fraudsters might navigate across multiple pages on a website differently from legitimate users. This navigation pattern is also known as a "user journey".
For example, on an online retail website, a fraudster might immediately navigate to the "account settings" section, and click on "saved payment methods" and "saved addresses". Consider this behavior repeated over hundreds of web sessions, and how different it would look from legitimate humans who would rarely need to examine their saved credit card profiles.
As another example, consider when you last manually logged out from a website. Only a small percentage of legitimate users bother to log out. However, if you are a fraudster and you need to access multiple accounts, you will likely log out every single time you need to switch accounts, or simply use your browser's incognito mode all the time.
The video below illustrates concisely how legitimate human users might navigate a travel website (such as booking.com) differently from fraudsters:
Visualizing user interactions - humans vs. bots. Adapted from a webinar in 2021 titled "Fake Reservation Story: The Power of Signals & Sharing Data" by Dan Woods, VP Shape Intelligence Center, F5 Networks. Original Youtube video: https://www.youtube.com/watch?v=LuDBTlkSKE4
Fraudsters often exhibit sufficiently different behavior in the aggregate
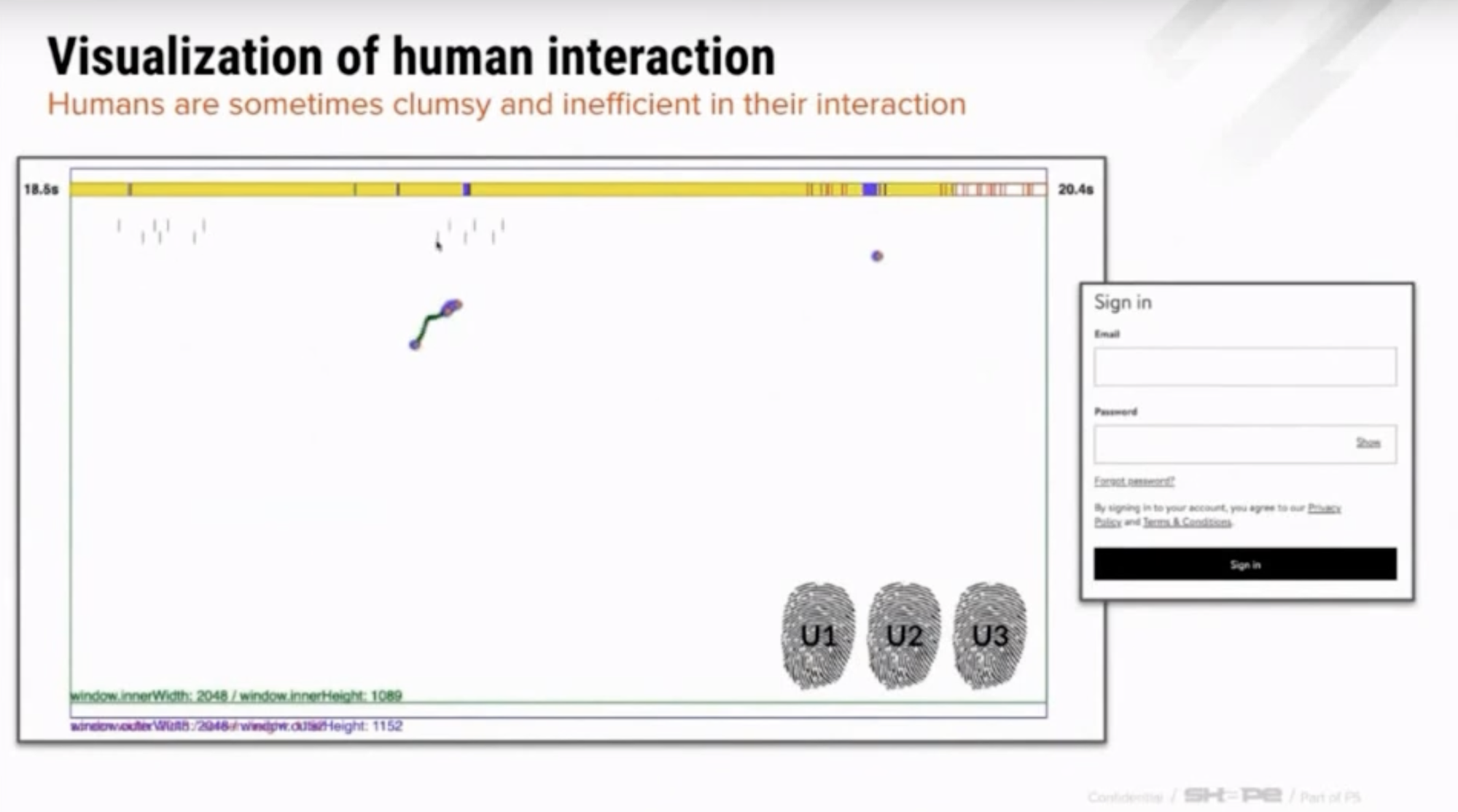
Here is another example. The following diagram is a highly stylized representation of a large North American bank's online banking login. It shows how humans and fraudsters would approach the same login form:
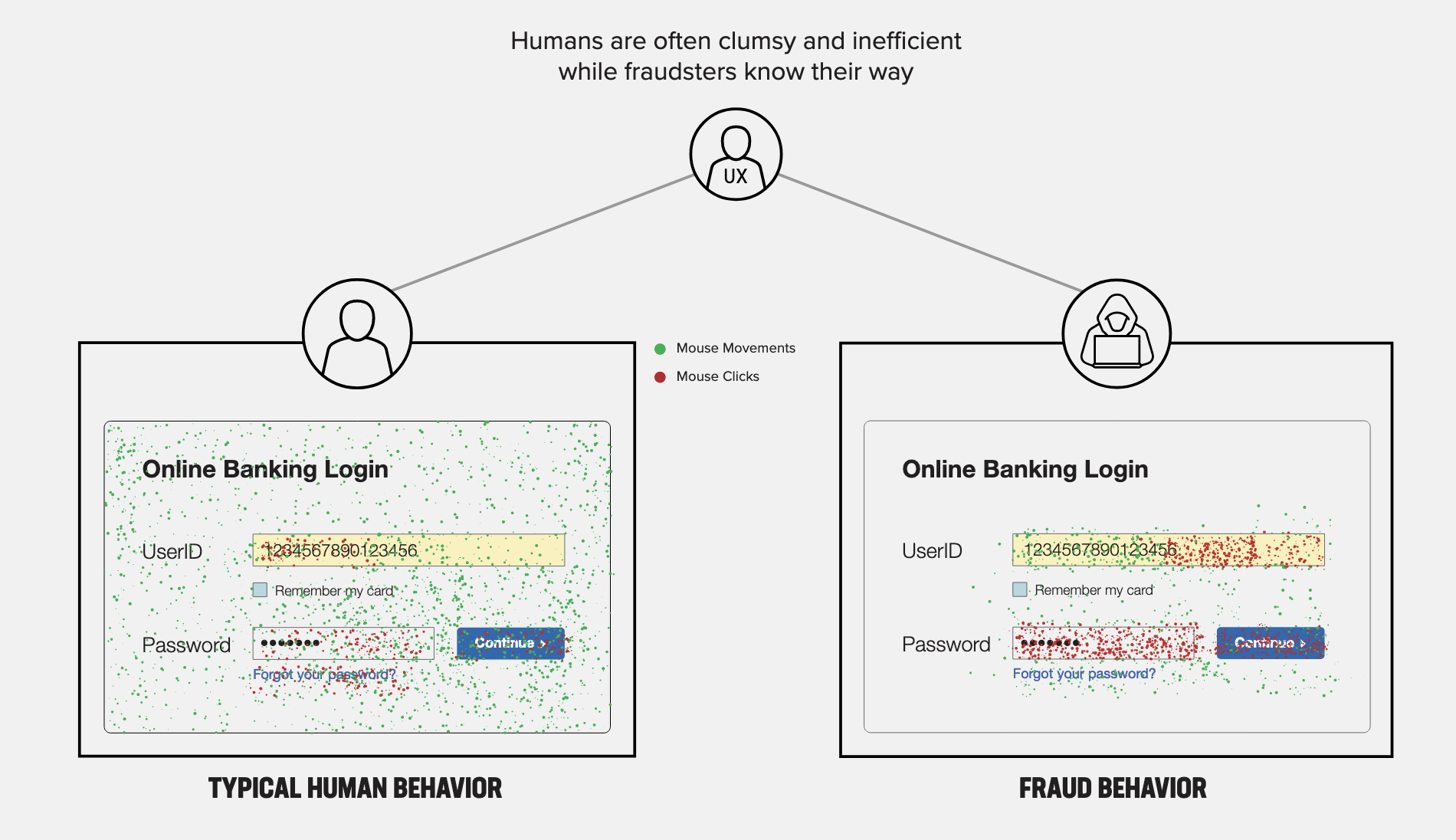
Once again, the green and red dots represent mouse movements and clicks. For legitimate humans (on the left), the "UserID" and "password" fields have very few clicks. This could be because most users would be returning to the same online banking website over and over again, and most users would have their usernames (and their passwords!) saved in the browser. In fact, it is very common for browsers to automatically fill in credentials and trigger a login -- hence there are not many clicks on the "Continue" button as well.
On the other hand, fraudsters show significant click activity in the UserID and password boxes. This could be explained by the likely scenario that fraudsters need to access multiple accounts (likely multiple accounts that are new to them) and therefore do not have account details saved in their browsers.
If you look closely, you will notice that the clicks in the UserID box are only on the right-hand side of the box. This is very specific to this particular instance: The bank in question has users using their 16-digit card numbers to log in. Now, the first six digits of a bank's card are likely to stay the same (this is the "BIN", which is fixed for a bank). The next few digits are also likely to remain constant, as they represent account numbers that have a very similar format across multiple accounts. The fraudsters were probably modifying only the last couple of digits on the card number – certainly, the last digit has to be changed with each new card number (as it is a "checksum" digit, which is computed based on the first 15 digits). The second or third last digits will also probably be changed each time, as they represent the account number. The password field is also heavily used.
Member discussion